SQL Data Lens is optimised for the unique features of InterSystems IRIS & Caché. It combines many tools with an intelligent SQL editor to provide easy access to your databases.
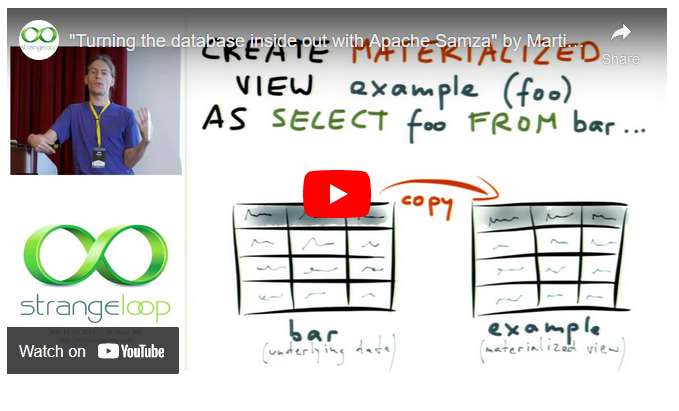
Kappa Architecture is a software architecture pattern. Rather than using a relational DB like SQL or a key-value store like Cassandra, the canonical data store in a Kappa Architecture system is an append-only immutable log. From the log, data is streamed through a computational system and fed into auxiliary stores for serving.
Kappa Architecture is a simplification of Lambda Architecture. A Kappa Architecture system is like a Lambda Architecture system with the batch processing system removed. To replace batch processing, data is simply fed through the streaming system quickly.
But why?
Kappa Architecture revolutionizes database migrations and reorganizations: just delete your serving layer database and populate a new copy from the canonical store! Since there is no batch processing layer, only one set of code needs to be maintained.
The purpose of the serving layer is to provide optimized responses to queries. These databases aren’t used as canonical stores: at any point, you can wipe them and regenerate them from the canonical data store. Almost any database, in-memory or persistent, might be used in the serving layer. This also includes special-purpose databases, e.g. for full text search.
Strange Loop is a multi-disciplinary conference that brings together the developers and thinkers building tomorrow’s technology in fields such as emerging languages, alternative databases, concurrency, distributed systems, security, and the web.
Strange Loop was created in 2009 by software developer Alex Miller and is now run by a team of St. Louis-based friends and developers under Strange Loop LLC, a for-profit venture.
Some of our guiding principles: No marketing. Keynotes are never sold to sponsors. The conference mailing lists are never sold or given to sponsors. Tech, not process. Talks are in general code-heavy, not process-oriented (agile, testing, etc). There are many fine speakers, topics, and conferences in the process area. This is not one of them. Technology stew. Interesting stuff happens when you get people from different areas in the same room. Strange Loop has a broad range of topics from academia, industry, and a touch of weirdness.
Apache Impala vs Presto: What are the differences?
What is Apache Impala?Real-time Query for Hadoop. Impala is a modern, open source, MPP SQL query engine for Apache Hadoop. Impala is shipped by Cloudera, MapR, and Amazon. With Impala, you can query data, whether stored in HDFS or Apache HBase – including SELECT, JOIN, and aggregate functions – in real time.
What is Presto?Distributed SQL Query Engine for Big Data. Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Why doesn’t SSAS cache the entire cube? Also, if you cube is much larger than the memory available to SSAS, then you would expect to see continual IO, and it is likely to be quite well optimised. However, when you have a 64 bit server with a cube that is larger than 3GB but is comfortably less than the server memory, you might be surprised to see the volume of continual IO.
Best Practices for Performance Tuning in SSAS Cubes, you are in right place. Define cascading attribute relationships, for example, day > Month > Quarter > year and define user hierarchies of related attributes (called natural hierarchies) within each dimension as Appropriate for your data
Best Practices for Performance Tuning in SSAS Cubes, you are in right place. Define cascading attribute relationships, for example, day > Month > Quarter > year and define user hierarchies of related attributes (called natural hierarchies) within each dimension as Appropriate for your data
Remove redundant relationships between attributes to assist the query execution engine in generating the appropriate query plan. Attributes need to have either a direct or an indirect relationship to key attributes, not both.
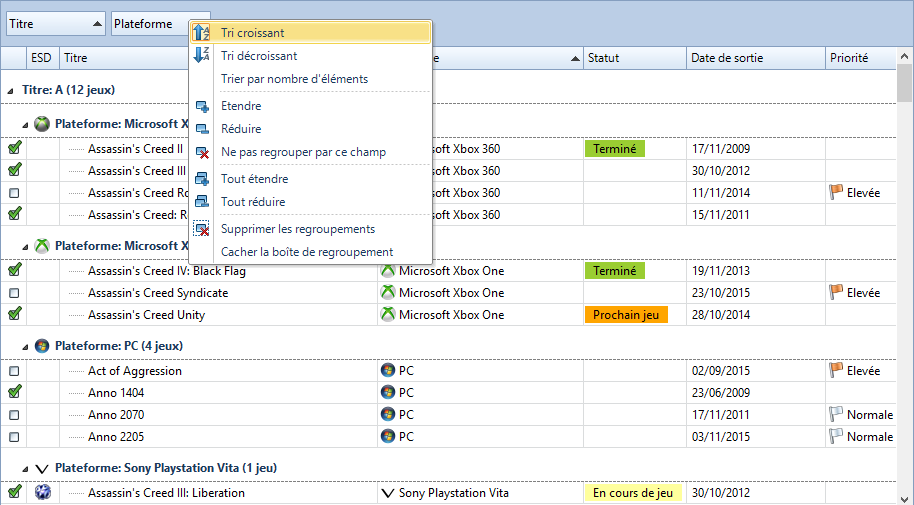
Krypton customized version of the .NET Winforms DataGridView (C#) that allows multi-grouping and multi-sorting. Featuring a TreeGrid mode, conditional formatting and additional custom columns. https://github.com/Cocotteseb/Krypton-OutlookGrid
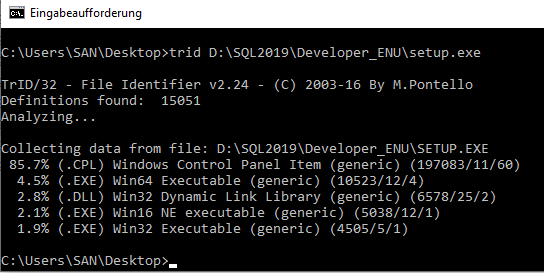
TrID is an utility designed to identify file types from their binary signatures. While there are similar utilities with hard coded logic, TrID has no fixed rules. Instead, it’s extensible and can be trained to recognize new formats in a fast and automatic way.