Utility to resolve SQL Server callstacks to their correct symbolic form using just PDBs and without a dump file
https://github.com/arvindshmicrosoft/SQLCallStackResolver
More Details:
Utility to resolve SQL Server callstacks to their correct symbolic form using just PDBs and without a dump file
https://github.com/arvindshmicrosoft/SQLCallStackResolver
More Details:
This article provides in-depth information on how to identify and resolve issues related to spinlock contention in SQL Server applications on high-concurrency systems.
https://docs.microsoft.com/en-us/sql/relational-databases/diagnose-resolve-spinlock-contention?view=sql-server-ver15
In the past, commodity Windows Server computers have utilized only one or two microprocessor/CPU chips, and CPUs have been designed with only a single processor or „core“. Increases in computer processing capacity have been achieved through the use of faster CPUs, made possible largely through advancements in transistor density. Following „Moore’s Law“, transistor density or the number of transistors that can be placed on an integrated circuit have consistently doubled every two years since the development of the first general purpose single chip CPU in 1971. In recent years, the traditional approach of increasing computer processing capacity with faster CPUs has been augmented by building computers with multiple CPUs. As of this writing, the Intel Nehalem CPU architecture accommodates up to eight cores per CPU, which when used in an eight socket system can then be doubled to 128 logical processors through the use of hyper-threading technology. As the number of logical processors on x86 compatible computers increases, concurrency-related issues increase as logical processors compete for resources. This guide describes how to identify and resolve particular resource contention issues observed when running SQL Server applications on high concurrency systems with some workloads.
In this section, we will analyze the lessons learned by the SQLCAT team from diagnosing and resolving spinlock contention issues. Spinlock contention is one type of concurrency issue observed in real customer workloads on high scale systems.
This guide describes how to identify and resolve latch contention issues observed when running SQL Server applications on high concurrency systems with certain workloads.
https://docs.microsoft.com/en-us/sql/relational-databases/diagnose-resolve-latch-contention?view=sql-server-ver15
As the number of CPU cores on servers continues to increase, the associated increase in concurrency can introduce contention points on data structures that must be accessed in a serial fashion within the database engine. This is especially true for high throughput/high concurrency transaction processing (OLTP) workloads. There are a number of tools, techniques, and ways to approach these challenges as well as practices that can be followed in designing applications which may help to avoid them altogether. This article will discuss a particular type of contention on data structures that use spinlocks to serialize access to these data structures.
This white paper introduces Google BigQuery, a fully-managed and cloudbased interactive query service for massive datasets. BigQuery is the external
https://cloud.google.com/files/BigQueryTechnicalWP.pdf
implementation of one of the company’s core technologies whose code name
is Dremel. This paper discusses the uniqueness of the technology as a cloudenabled massively parallel query engine, the differences between BigQuery
and Dremel, and how BigQuery compares with other technologies such as
MapReduce/Hadoop and existing data warehouse solutions.
Implementation of an MPP SQL query engine for the Hadoop environment•Designed for performance: brand-new engine, written in C++•Maintains Hadoop flexibility by utilizing standard Hadoop components (HDFS, Hbase, Metastore, Yarn)•Reads widely used Hadoop file formats (e.g. Parquet, Avro, RC, …)•Runs on same nodes that run Hadoop processes•Plays well with traditional BI tools:exposes/interacts with industry-standard interfaces (odbc/jdbc, Kerberos and LDAP, ANSI SQL)
http://cidrdb.org/cidr2015/Slides/28_CIDR15_Slides_Paper28.pdf
Delta Lake is an open-source storage layer that brings ACID
https://delta.io/
transactions to Apache Spark™ and big data workloads.
All data in Delta Lake is stored in Apache Parquet format enabling Delta Lake to leverage the efficient compression and encoding schemes that are native to Parquet.
Presto is an open source distributed SQL query engine for running interactive analytic queries against data sources of all sizes ranging from gigabytes to petabytes.
Presto was designed and written from the ground up for interactive analytics and approaches the speed of commercial data warehouses while scaling to the size of organizations like Facebook.
https://prestodb.io/
In this paper, we describe the Polaris distributed SQL query engine
https://www.vldb.org/pvldb/vol13/p3204-saborit.pdf
in Azure Synapse. It is the result of a multi-year project to rearchitect the query processing framework in the SQL DW parallel
data warehouse service, and addresses two main goals: (i) converge
data warehousing and big data workloads, and (ii) separate compute
and state for cloud-native execution.
Zwei Programmierer entwarfen nahezu im Alleingang ein Betriebssystem und die Sprache C: https://www.golem.de/news/unix-wird-50-die-wilde-jugend-von-unix-2006-149027.html
Space Travel created and published by AT&T in 1969, running on DEC PDP-1 https://www.uvlist.net/game-164857-Space+Travel
Byte-magazine-1983-08: https://archive.org/stream/byte-magazine-1983-08/1983_08_BYTE_08-08_The_C_Language#page/n189/mode/2up
Das man solche oder ähnlich nette Hinweise per Mail erhält… Geschenkt! Auch nette Service Mails der eigenen Bank doch schnell mal die Adressdaten zu überprüfen und das mit einer TAN zu bestätigen… geschenkt!
Als ich mich nun bei meinem Hoster anmeldete und das hier las wurde ich kurz nervös:
Ups! Was ist denn da kaputt!? Schnell mal die Details anschauen!
Ein echtes Problem?! … weit gefehlt! Es ist leider leider (oder zum Glück??) nur ein Versuch von Seiten 1und1 seine eigenen Kunden zu verunsichern und Ihnen so mehr Geld aus der Tasche zu ziehen.
Auf der nächsten Seite erkennt man die Details:
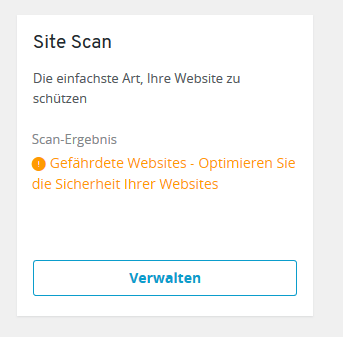
Zitat: „Wir kümmern uns um die Sicherheit Ihrer Website – Aus diesem Grund arbeiten wir mit Site Lock und führen automatisch einen Scan für alle Ihre Websites durch. Durch den automatischen Scan haben wir bereits eine potenzielle Schwachstelle auf 3 Websites gefunden.„
Zunächst sagt mir 1und1: „Gefährdete Websites gefunden!“
Um mich dann darauf hinzuweisen: „Es gibt derzeit keine Schwachstellen zu beseitigen„
Es wird versucht den Kunden zu verunsichern und mit pseudo Warnhinweisen zum Abschluss eines kostenpflichtiges Paketes zu bewegen. Mit diesem Vorgehen baut man kein Vertrauensverhältnis auf. Ein echter Warnhinweis wird so in seiner wichtigkeit herabgestuft, da evtl. nicht mehr wahrgenommen.
Liebe 1&1 … IONOS… what ever: Kann man so machen… muss man aber nicht :-(