Like most software patterns, few of them are gold standards that all teams should follow. Software development workflow is very dependent on context, in particular the social structure of the team and the other practices that the team follows.
https://martinfowler.com/articles/branching-patterns.html
In thinking about these patterns, I find it useful to develop two main categories. One group looks at integration, how multiple developers combine their work into a coherent whole. The other looks at the path to production, using branching to help manage the route from an integrated code base to a product running in production.
Kategorie: Dev
Microsoft JDBC Driver for SQL Server
The Microsoft JDBC Driver for SQL Server is a Type 4 JDBC driver that provides database connectivity through the standard JDBC application program interfaces (APIs) available in the Java Platform, Enterprise Editions. The Driver provides access to Microsoft SQL Server and Azure SQL Database from any Java application
Microsoft ADO.NET driver for SQL Server
Microsoft ADO.NET driver for SQL Server aka the Microsoft.Data.SqlClient GitHub repository.
Microsoft.Data.SqlClient is a data provider for Microsoft SQL Server and Azure SQL Database. Now in General Availability, it is a union of the two System.Data.SqlClient components which live independently in .NET Framework and .NET Core. Going forward, support for new SQL Server features will be implemented in Microsoft.Data.SqlClient
Standalone SQL Server Integration Services (SSIS) DevOps Tools
Standalone SSIS DevOps Tools provide a set of executables to do SSIS CICD tasks. Without the dependency on the installation of Visual Studio or SSIS runtime, these executables can be easily integrated with any CICD platform. The executables provided are:
SSISBuild.exe: build SSIS projects in project deployment model or package deployment model.
SSISDeploy.exe: deploy ISPAC files to SSIS catalog, or DTSX files and their dependencies to file system.
ASQA Analysis Services Query Analyzer
Looks a little outdated at first…
Troubleshooting MDX queries can be a complex and time-consuming activity that requires the manual execution of many and repetitive tasks using different tools. Using Analysis Services Query Analyzer, you can forget all the complexities and drastically reduce the time spent to execute your analysis.
https://ssasqueryanalyzer.github.io/
Analysis Services Query Analyzer (ASQA) is a complete FREE tool distributed under the MIT license and its source code is published on GitHub https://github.com/SSASQueryAnalyzer/SSASQueryAnalyzer
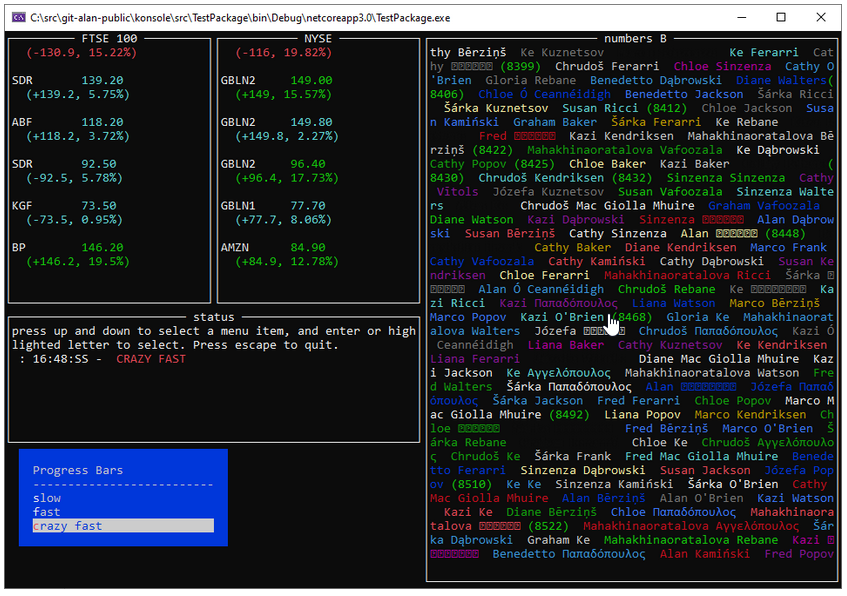
Konsole V6
Low ceremony, Fluent DSL for writing console apps, utilities and spike projects. Providing thread safe progress bars, windows and forms and drawing for console applications. Build UX’s as shown below in very few lines of code. Konsole provides simple threadsafe ways to write to the C# console window.
https://github.com/goblinfactory/konsole
Integration Services Programming Overview
SQL Server Integration Services has an architecture that separates data movement and transformation from package control flow and management. There are two distinct engines that define this architecture and that can be automated and extended when programming Integration Services. The run-time engine implements the control flow and package management infrastructure that lets developers control the flow of execution and set options for logging, event handlers, and variables. The data flow engine is a specialized, high performance engine that is exclusively dedicated to extracting, transforming, and loading data. When programming Integration Services, you will be programming against these two engines.
https://docs.microsoft.com/en-us/sql/integration-services/integration-services-programming-overview?view=sql-server-ver15

In this article, we will first illustrate how to create, save and execute SSIS packages using ManagedDTS in C#, then we will do a small comparison with Biml.
https://www.sqlshack.com/biml-alternatives-building-ssis-packages-programmatically-using-manageddts/
Why I No Longer Use MVC Frameworks
The worst part of my job these days is designing APIs for front-end developers. The conversation goes inevitably as:
https://www.infoq.com/articles/no-more-mvc-frameworks/
Dev – So, this screen has data element x,y,z… could you please create an API with the response format {x: , y:, z: }
Me – Ok
I don’t even argue anymore. Projects end up with a gazillion APIs tied to screens that change often, which, by “design” require changes in the API and before you know it, you end up with lots of APIs and for each API many form factors and platform variants. Sam Newman has even started the process of institutionalizing that approach with the BFF pattern that suggests that it’s ok to develop specific APIs per type of device, platform and of course versions of your app. Daniel Jacobson explains that Netflix has been cornered to use a new qualifier for its “Experience APIs”: ephemeral. Sigh…
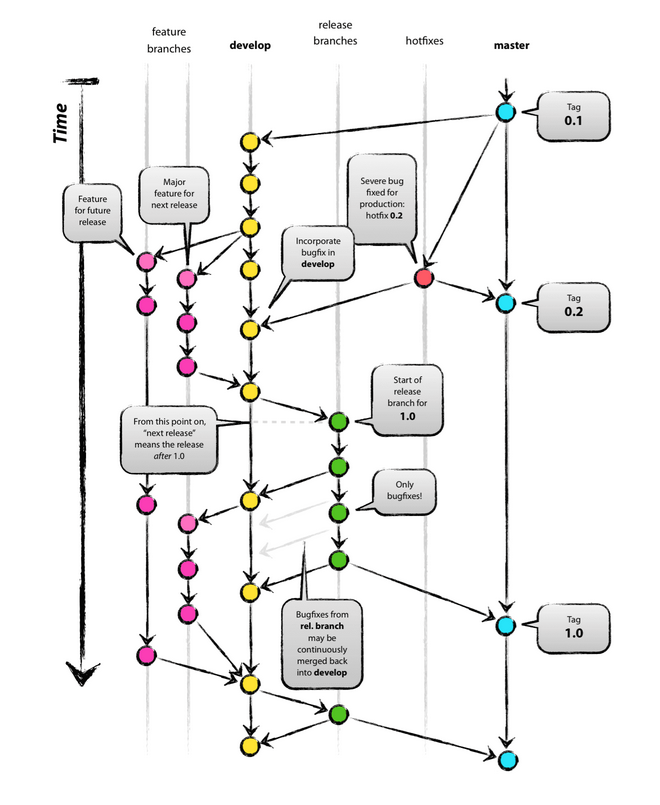
A successful Git branching model
If, however, you are building software that is explicitly versioned, or if you need to support multiple versions of your software in the wild, then git-flow may still be as good of a fit to your team as it has been to people in the last 10 years. In that case, please read on.
https://nvie.com/posts/a-successful-git-branching-model/
Jim Gray Summary Home Page
James Nicholas Gray (1944 – declared dead in absentia 2012) was an American computer scientist who received the Turing Award in 1998 „for seminal contributions to database and transaction processing research and technical leadership in system implementation“
https://en.wikipedia.org/wiki/Jim_Gray_%28computer_scientist%29
